Prácticos
Lleva la inteligencia artificial a tu PC con LM Studio
Si 2023 fue el año de los servicios basados en inteligencia artificial, 2024 va a serlo de la IA en el dispositivo, es decir, del traslado del cómputo asociado a los modelos a nuestro PC, smartphone, etcétera. Esto, principalmente, lo encontraremos en aplicaciones que incorporan funciones basadas en IA, pero también tenemos software en el que la inteligencia artificial es el fin en sí mismo, como ocurre con LM Studio, que nos permite probar una gran cantidad de modelos de lenguaje extensos (LLM).
Esto, seguramente, te resultará familiar por otras opciones como Chat with RTX, una aplicación de la que ya te hablamos hace unas semanas y que sigue el modelo de hacer que su uso sea lo más sencillo, es decir, instalar y empezar a «hablar» con el modelo (aunque también permite realizar algún ajuste adicional, como sumar tus propios datos para personalizar la respuesta del modelo). Si tienes una tarjeta gráfica de las series RTX 30 o RTX 40 con 8 gigabytes de VRAM, podrás emplear Mistral 7B INT4, y también Llama2 13B INT4 en configuraciones un poco más elevadas.
LM Studio no es tan sencillo de emplear (aunque no temas, tampoco es especialmente complicado), pero a cambio de ello proporciona acceso a una enorme cantidad de modelos, la posibilidad de realizar múltiples ajustes de configuración sobre el funcionamiento de los mismos en las conversaciones, incluso podemos poner en funcionamiento un servidor local que podremos emplear para, de este modo, proporcionar el servicio de inferencia del modelo a nuestros propios desarrollos.

Requisitos técnicos
En este punto debemos distinguir entre lo que es imprescindible y lo que resulta recomendable, pues sin lo primero no podremos utilizar LM Studio, mientras que lo segundo será determinante en la velocidad de inferencia del modelo que hayamos seleccionado. El grupo de los primeros está conformado por estas tres, y tengamos en cuenta que hablamos de mínimos:
- 16 gigabytes de memoria RAM.
- GPU con 6 gigabytes de memoria VRAM.
- Procesador con soporte AVX2.
He leído alguna referencia de usuarios que afirman haber empleado LM Studio en un sistema con ocho gigabytes de RAM, y también en un PC con un adaptador gráfico que no llega a los 6 gigabytes de VRAM, pero incluso si en unas condiciones muy concretas resulta posible hacerlo, el rendimiento será tan excepcionalmente bajo que, en la práctica, será prácticamente inutilizable.
Otro elemento muy importante es contar con suficiente espacio de almacenamiento, y que éste sea rápido, mínimo SSD y más que recomendable SSD PCIe. Ten en cuenta, como ya habrás deducido y podrás comprobar al empezar a utilizarlo, debes descargar a tu PC los modelos que quieras emplear, y el tamaño de los mismos puede llegar a ser más que considerable.
El requisito más asumible es que el procesador cuente con el juego de instrucciones AVX2. Tengamos en cuenta que éste debutó en 2013, de la mano de la cuarta generación Intel Core (Haswell) y que en los integrados de AMD ha estado presente desde Excavator y la primera generación de la arquitectura Zen.
Si tu sistema cumple con estos requisitos, y quieres empezar a hacer pruebas ya, descarga LM Studio desde este enlace e instálalo siguiendo los pasos que te indicará el asistente. Como puedes comprobar en su web, hay versiones para Windows, macOS y Linux.
Huggin Face, modelos y model cards
Uno de los primeros pasos que debes llevar a cabo para empezar a utilizar LM Studio es descargar algún modelo. Pero para ello, claro, es imprescindible que conozcas el origen de los mismos y que puedas entender algunas especificaciones clave. Como verás más adelante, la aplicación intenta determinar si un LLM se puede emplear o no en tu PC, pero aún así es más que recomendable que sepas entender las razones de ello, y también qué ajustes puedes llevar a cabo.
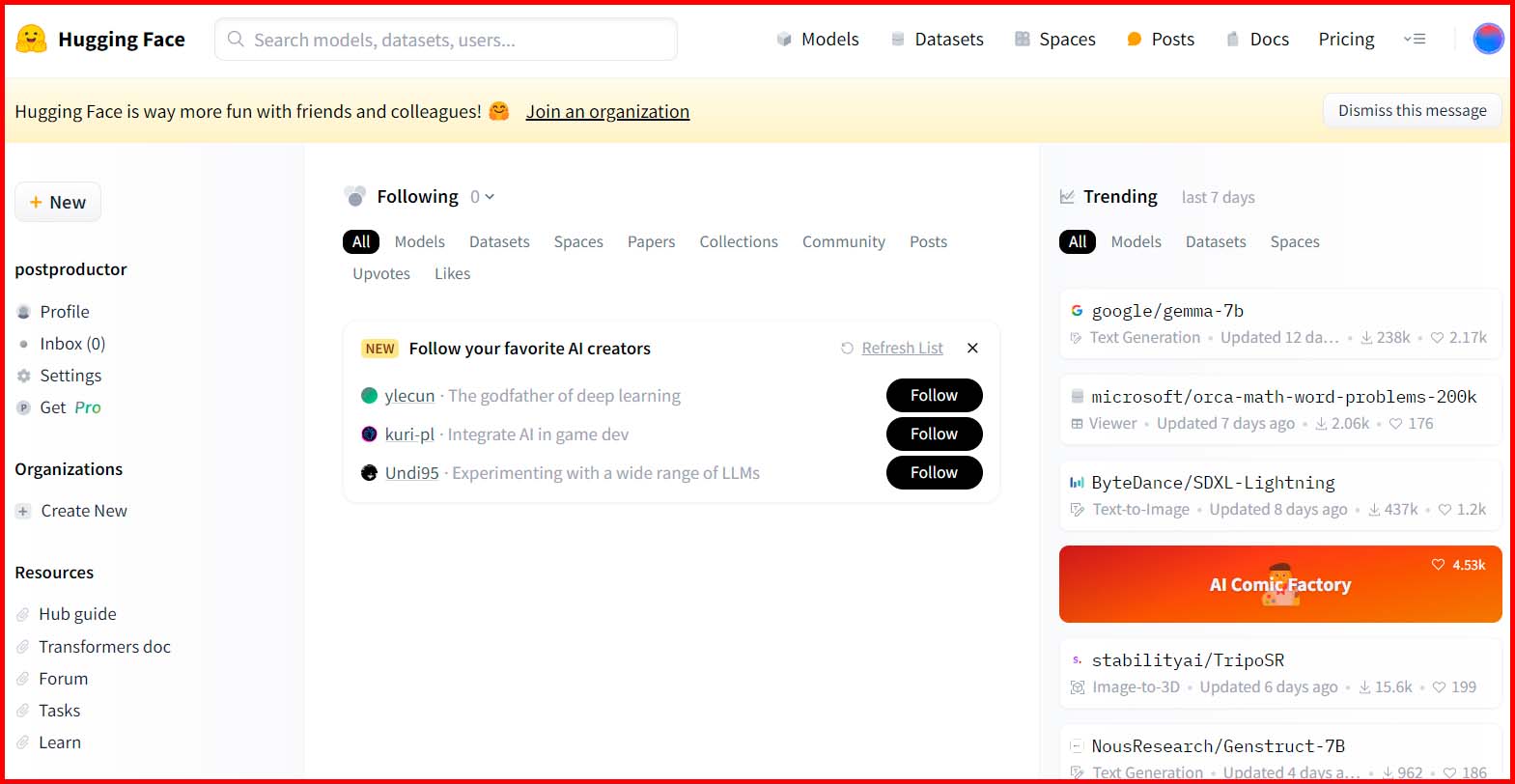
Así, debemos empezar por hablar de Huggin Face, el repositorio de modelos de IA desde el que LM Studio descargará aquellos que quieras emplear. Desde su sitio web puedes acceder a modelos, datasets, espacios para probar múltiples tipos de modelos generativos, foros, documentación técnica y más. Este es, sin duda, un sitio imprescindible para cualquier persona interesada en la inteligencia artificial, e incluso si no lo identificas por su nombre, es bastante probable que hayas accedido en alguna ocasión para probar alguna IA.
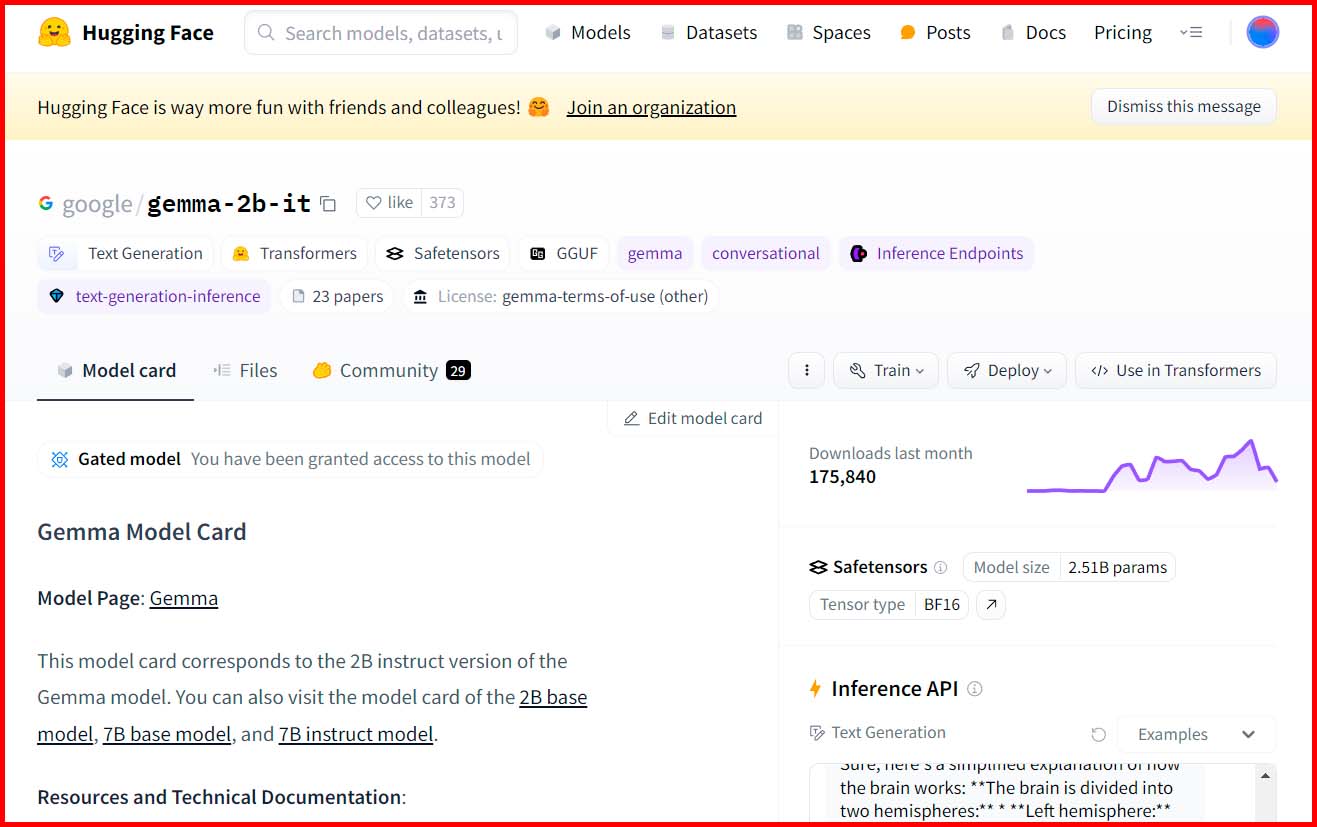
Para instalar un modelo en LM Studio no es necesario que accedas directamente a la web de Huggin Face, pero si necesitas información adicional sobre un LLM que estás pensando en instalar, el software te ofrece acceso directo a su model card en la web. ¿Y qué es una «model card»? Pues se trata de una ficha informativa sobre el mismo, en la que podrás encontrar información sobre su licencia, los archivos que lo componen, un espacio para hacer una prueba rápida de sus capacidades de inferencia, etcétera. Ésta es, siempre, una visita recomendable antes de instalar un modelo.
A la hora de elegir un modelo (o, en la inmensa mayoría de los casos, una de las múltiples variantes de uno), hay dos parámetros clave, que te informan sobre lo que puedes esperar del mismo, parámetros y cuantización.
- Parámetros: normalmente lo verás expresado como un número seguido de una letra B. Por ejemplo, 7B nos indica que se trata de un modelo con siete mil millones (siete billones americanos). En el contexto de un LLM que emplea una estructura de red neuronal, cada parámetro es el equivalente a una conexión neuronal. Así, ya lo habrás deducido, a mayor número de parámetros mayor densidad y, por ende, mayor rendimiento.
- Cuantización: técnica empleada para reducir el tamaño del modelo sin sacrificar el número de parámetros del mismo. Se expresa con un número precedido de una Q, por ejemplo Q8. Este valor nos indica el número de bits empleado por cada parámetro. De nuevo, a un mayor número de bits, se espera un mejor rendimiento del modelo, es decir, mejores respuestas.
Así pues, lo lógico sería optar siempre por el modelo con un mayor número de parámetros y el valor Q más alto, ¿no? Pues la respuesta es que sí, pero solo si cuentas con un pequeño datacenter en casa, pues como ocurre en otros muchos casos, rendimiento y eficiencia mantienen una relación inversamente proporcional. Por lo tanto, a la hora de elegir un modelo, especialmente si pretendes utilizarlo de manera habitual, tendrás que buscar el equilibrio entre un buen rendimiento del LLM pero, a la vez, que sea usable en tu ordenador sin que cada respuesta se eternice.
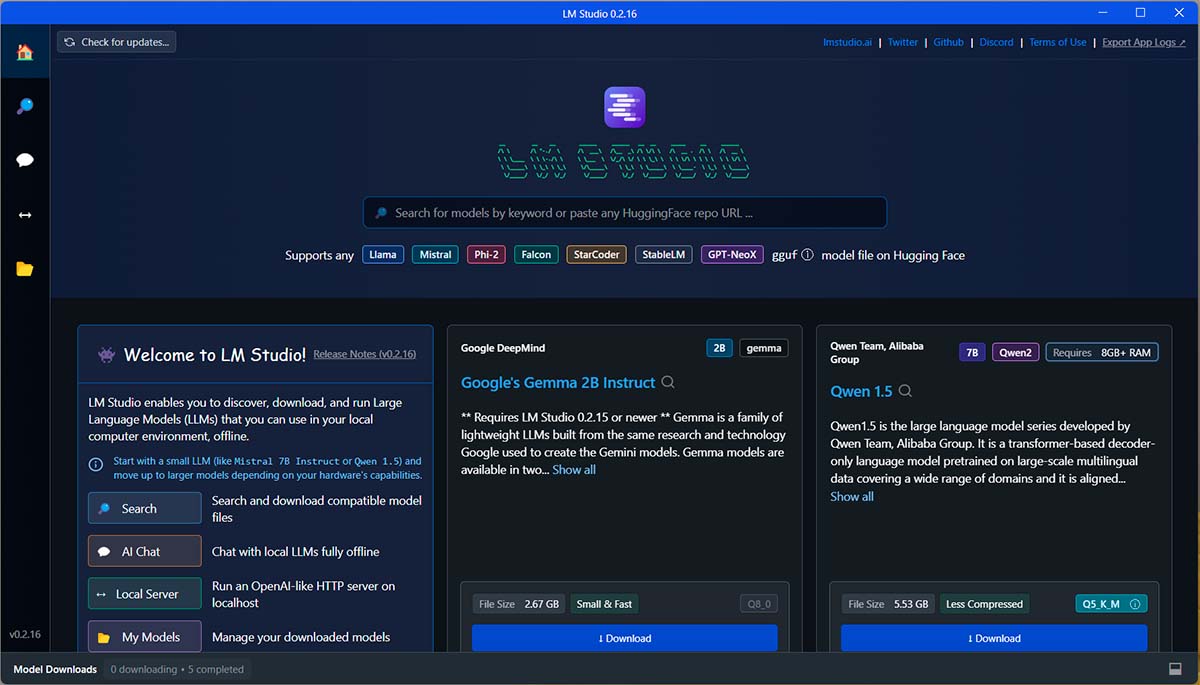
Primeros pasos con LM Studio
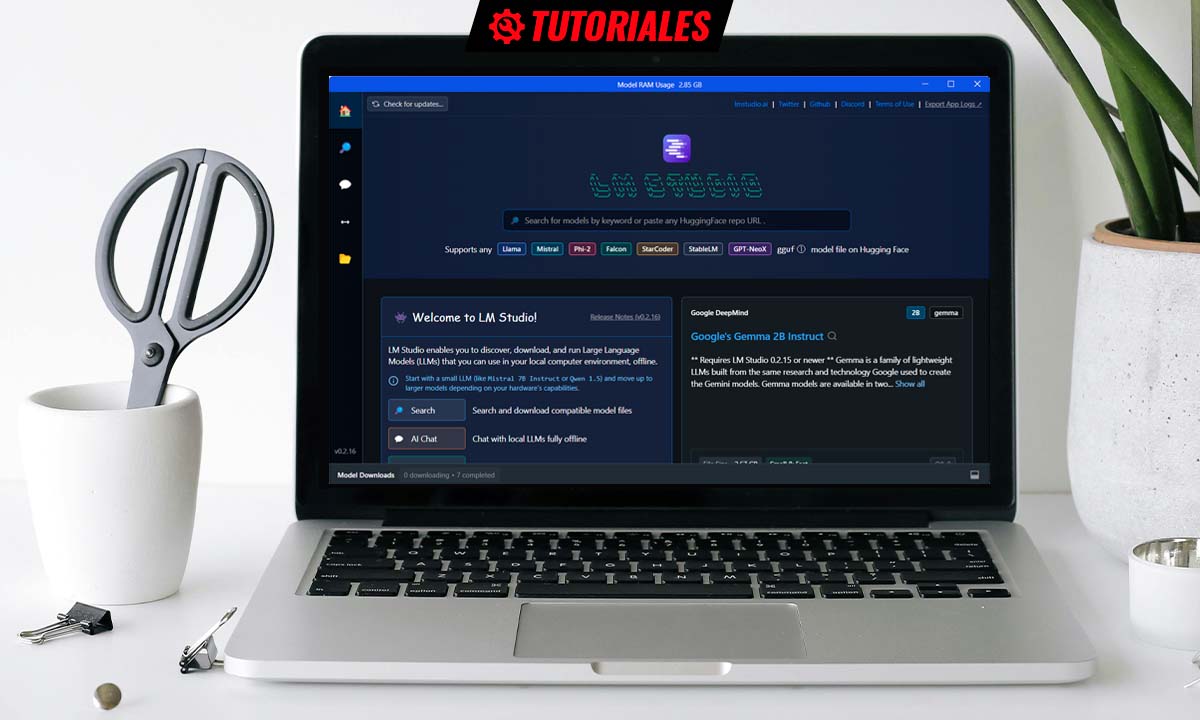
Como ya indiqué anteriormente, LM Studio es algo más complejo que Chat with RTX, que es una opción excelente para aquellos usuarios que deseen una experiencia de «instalar y listo». Sin embargo, esto no debe hacerte pensar que su manejo es complicado. Muy al contrario, verás que en unos pocos minutos ya sabes todo lo necesario para empezar a utilizarlo sin problemas. Así, cuando lo inicies por primera vez, se mostrará una ventana como la que puedes ver en la imagen superior.
Lo primero es, claro, instalar un primer modelo (puedes tener varios, claro, aunque solo podrás emplear uno en cada momento). Para empezar por uno ligero, mi recomendación es empezar por Gemma, de Google. Como puedes comprobar, en la actualidad se muestra directamente en la interfaz inicial de LM Studio, y puedes instalarlo con un solo click en el botón «Download»:

Sin embargo, y para que te puedas familiarizar más con la interfaz de la aplicación, aún sabiendo que podrías instalarlo de este modo, para esta primera toma de contacto vamos a emplear la función de búsqueda de modelos de la aplicación, pues es la herramienta que te proporciona acceso completo a todos los modelos disponibles.
Para tal fin, haz click en el icono con forma de lupa que se muestra en el lateral izquierdo de la ventana y, cuando se muestre ya la función de búsqueda, escribe «Gemma» en el recuadro que se muestra en la parte superior y haz click en «Go» (el botón se mostrará cuando empieces a escribir en el recuadro, no antes).
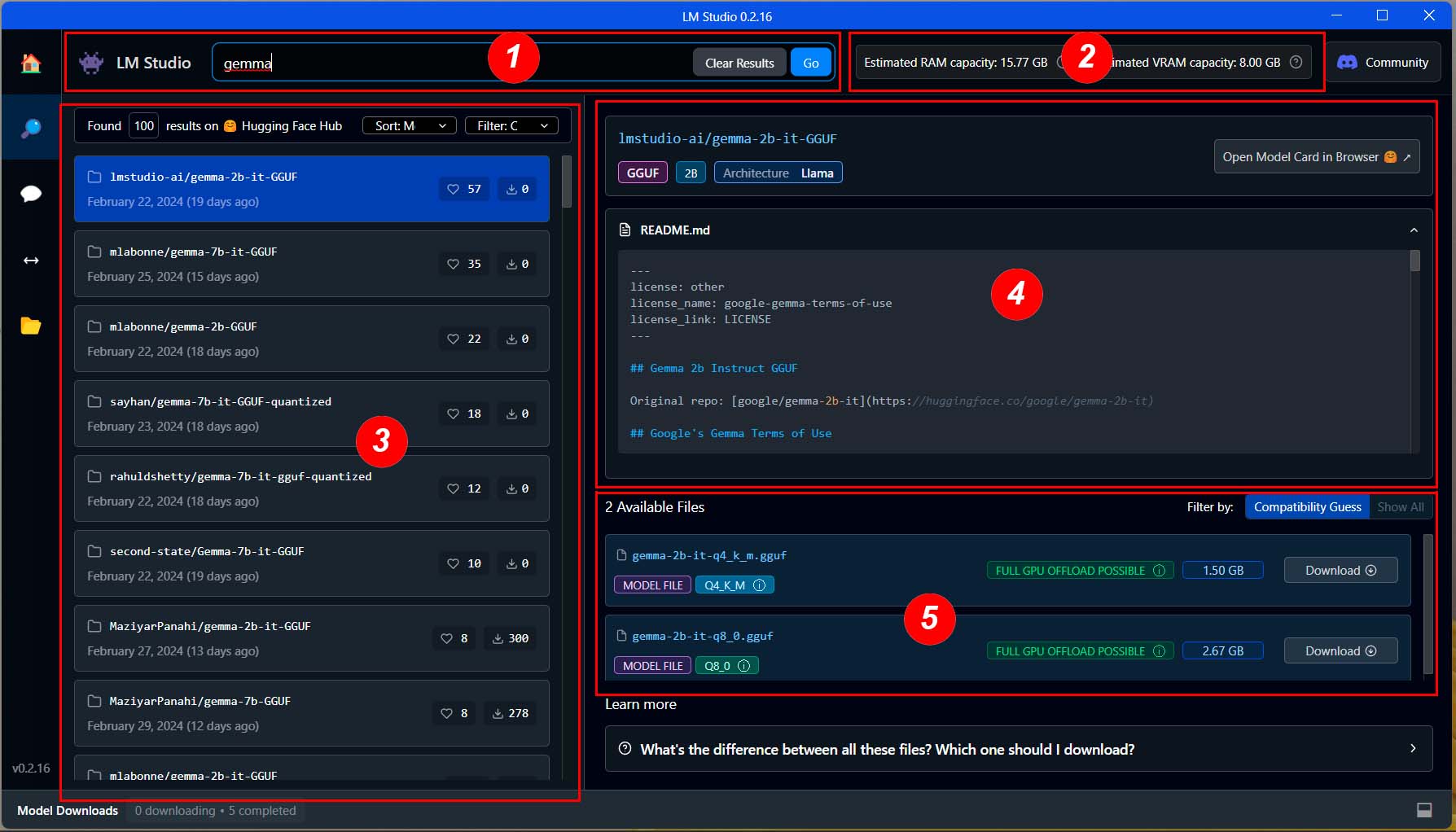
Veamos más, en detalle, los distintos elementos del apartado de búsqueda de LLM Studio:
- Barra de búsqueda: este es, ya lo habrás deducido, el apartado en el que te indicaba anteriormente que debes escribir lo que estás buscando, ya sea el nombre, algún término específico, etcétera.
- Información del sistema: aquí se muestra la información sobre la RAM y la VRAM que ha detectado el software en el sistema.
- Modelos encontrados: una vez que hayas pulsado el botón «Go», aquí se mostrarán todos los modelos encontrados en función del término de búsqueda empleado.
- Información del modelo seleccionado: en estos dos apartados puedes ver información básica sobre el modelo, el contenido de un archivo de texto con información sobre el mismo y, muy importante, el botón para revisar la model card de este modelo en Huggin Face.
- Variantes del modelo: un modelo puede contar con múltiples variantes que, en tal caso, se mostrarán en este apartado.
En este ejemplo concreto, como puedes ver, se muestran dos variantes y, si te fijas en su nombre, verás que ambas tienen dos mil millones de parámetros (2B), pero que una de ellas tiene un nivel de cuantización de 4 bits (Q4) y su tamaño es de 1,50 gigabytes, mientras que la otra tiene un nivel de cuantización de 8 bits (Q8) y su tamaño es de 2,57 gigabytes.
Por otra parte, posiblemente también te haya llamado la atención el indicador «FULL GPU OFFLOAD POSSIBLE». En la siguiente imagen puedes ver los tres mensajes que se pueden mostrar en cada variante de los modelos:

Vamos a emplear esta imagen, además de para explicar qué nos indica cada uno de estos mensajes, para hacer un ejercicio de lectura de los datos principales del modelo, lo que además nos lleva a hacer una puntualización sobre algo que hemos visto anteriormente.
Vamos a empezar por la lectura de los datos fundamentales de los tres modelos, ¿de acuerdo? Así, tenemos:
- gemma-2b-it-q8_0.gguf – Full GPU offload possible – 2,67 gigabytes.
- gemma-7b-it-Q6_K.gguf – Partial GPU offload possible – 7,01 gigabytes.
- gemma-7b-it-fp16.gguf – Likely to large for this machine – 17,08 gigabytes.
¿Ves algo que te llame la atención? Sí, efectivamente, en la tercera variante no se indica el nivel de cuantización y, en su lugar, leemos FP16. ¿Y qué nos indica esto? Bien, como recordarás, antes te indicaba que la cuantización es una técnica de optimización empleada para reducir considerablemente el tamaño de los modelos. Y aquí es cuando debes saber que, de no haber pasado por este proceso, cada parámetro se define por un valor numérico con decimales expresado en coma flotante (floating point, de ahí el FP en la descripción del modelo) y que puede ser de hasta 24 bits. Por su parte, en los modelos optimizados mediante esta técnica, los parámetros se convierten a enteros, algo que juega un papel clave en la reducción de tamaño.
Así, mientras que los dos primeros modelos de la lista han visto sus parámetros sometidos a un proceso de cuantización, en el tercero esto no ha ocurrido, y en su lugar se expresan con números con decimales, expresados en coma flotante, con un tamaño de 16 bits (FP16) por parámetro.
Hecha esta importante aclaración, veamos qué significan estos tres mensajes, que además nos hablan de la importancia de la memoria RAM del sistema y, aún más especialmente, de la VRAM de la GPU. Por una serie de razones, la IA se lleva mejor con las GPU que con la CPU, y esto se extiende también a la memoria. Y, por otra parte, también debes saber que el modelo, entero, debe cargarse en memoria para que puedas empezar a utilizarlo. Y, claro, en función de la memoria disponible y el tamaño del modelo, es posible emplear solo la VRAM o combinarla con la RAM del sistema.
- Full GPU offload possible: parece posible cargar todo el modelo en la VRAM de la GPU.
- Partial GPU offload possible: podrás cargar parte del modelo en la VRAM de la GPU, y el resto en la RAM del sistema.
- Likely to large for this machine: la cantidad total de memoria del sistema (VRAM + RAM) parece insuficiente para ejecutar el modelo.
Obviamente, lo ideal es optar por modelos que se puedan alojar por completo en la VRAM, pero si tienes curiosidad también puedes probar alguno de los intermedios y, una vez instalado, ajustar la distribución (más adelante te explico cómo hacerlo).
Extra: seguro que has escuchado hablar, estos últimos tiempos, sobre modelos LLM sin censura, y quizá te estés preguntando si esta es una posibilidad presente en LM Studio. La respuesta es que sí, puedes probar modelos sin censura, aunque evidentemente mi recomendación es que los utilices con cabeza y, desde luego, nunca para hacer el mal. Dicho lo cual, para experimentar esta posibilidad emplea el término «uncensored» en el buscador de modelos.
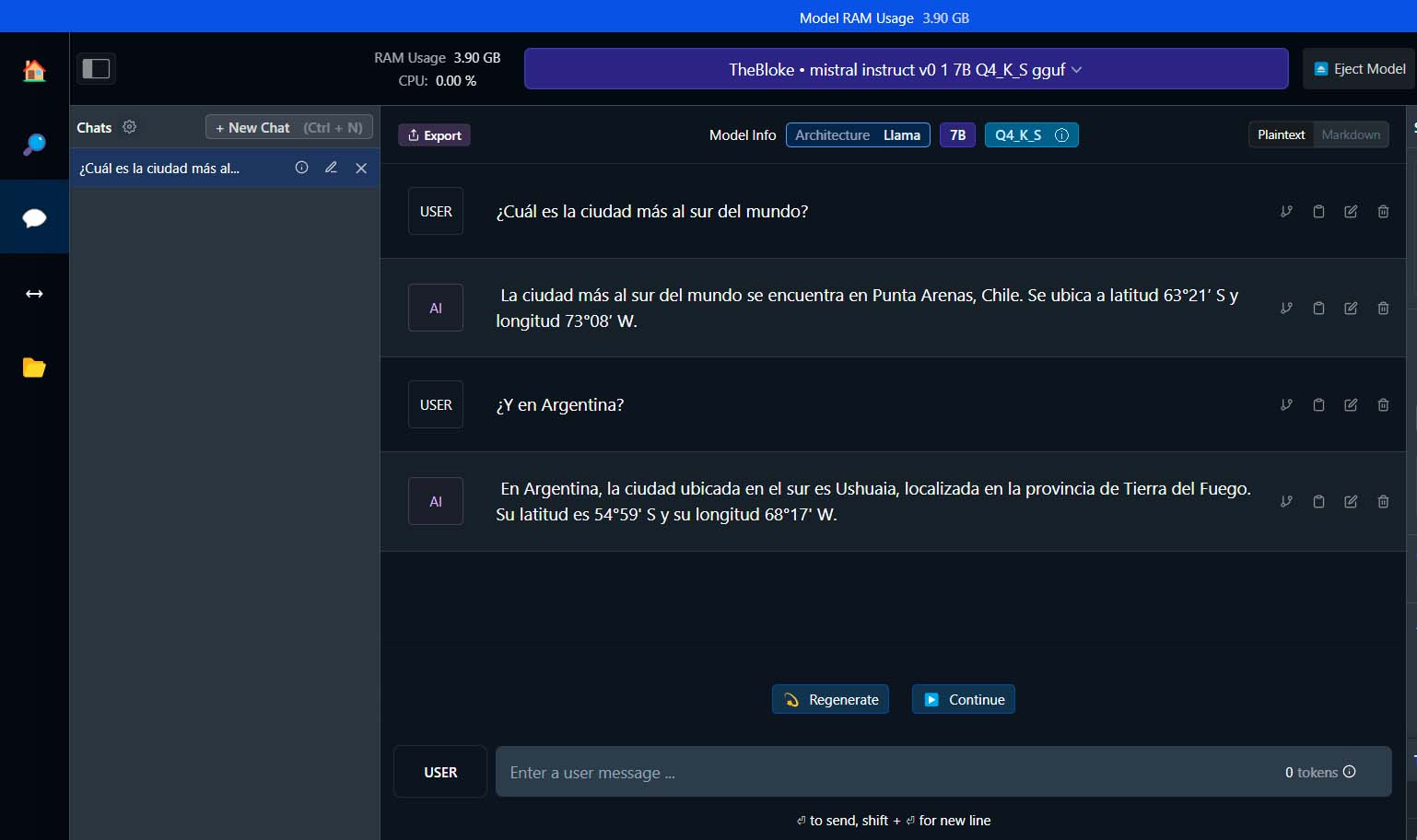
Primera conversación
Llegados a este punto, seguro que estás deseando empezar a probar el modelo que acabas de instalar, ¿verdad? No te preocupes, la espera ha terminado, así que vamos allá con tu primera «conversación» con una IA que se está ejecutando, íntegramente, en tu PC, con LM Studio. Para ello, en primer lugar haz click, en la barra de menú del lateral izquierdo, en el icono que representa los chats mediante un bocadillo. Esto te llevará, automáticamente, a dicho apartado.

Como ya habrás deducido, el primer paso que debes dar es seleccionar el LLM que quieres emplear en esta conversación. Para ello haz click, en la parte superior central de la ventana, en «Select a model to load». De este modo, se mostrará un menú con los modelos que hayas descargado a tu PC. Haz click en el que quieras emplear y, automáticamente, empezará a cargarse en memoria. No obstante, si antes se muestra el mensaje (que, con total seguridad, sí que se mostrará en futuros usos de LM Studio cuando modifiques configuraciones y/o cambies de un modelo a otro)
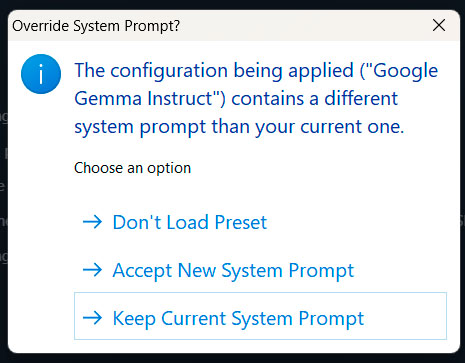
en tal caso puedes mantener la configuración actual o, si lo prefieres, cargar la asociada al modelo, en función de tus preferencias. En los primeros usos, y para ir sobre seguro, lo mejor es que escojas «Accept New System Prompt», aunque luego lleves a cabo alguna modificación. Ahora sí, se iniciará la carga del modelo:

En función del tamaño del modelo y de las especificaciones técnicas de tu PC, este proceso tardará más o menos tiempo. Con un LLM ligero y optimizado, como Gemma 2B, en la mayoría de los casos será cuestión de unos pocos segundos. Una vez completado este proceso, los datos del modelo se mostrarán bajo el selector y LM Studio ya estará listo para que empieces a conversar

Solo vamos a realizar un ajuste de configuración antes de iniciar la conversación. ¿Recuerdas que antes vimos que podías cargar todo o parte del modelo en la VRAM de la GPU? Pues ahora vamos a ajustar precisamente eso, cuánto del modelo irá a la RVAM y qué parte se quedará en la RAM. Para ello localiza, en el lateral derecho, el apartado

Como ya habrás imaginado, lo primero que debes hacer es activar «GPU Offload» y, a continuación, emplea la barra deslizante para ajustar dicha distribución, teniendo en cuenta que la posición de la izquierda «envía» todo el modelo a la RAM del sistema, y que a medida que la desplazas a la derecha estarás seleccionando un mayor uso de la VRAM. Lo ideal, si se indicaba que el modelo se podía cargar por completo en la misma, es que desplaces la barra totalmente a la derecha, o que hagas click en el botón «Max» que se muestra bajo la barra. En caso contrario, si se indicaba que se podía cargar parcialmente, lo recomendable es que vayas probando con distintos ajustes (de menos a más) hasta encontrar el punto dulce.
Ten en cuenta, eso sí, que al hacer cualquier modificación en la configuración tendrás que volver a cargar el modelo. Para tal fin, verás que en la parte inferior del apartado central de la ventana se muestra un botón con el texto «Reload model to apply configuration». Haz click en él y este proceso se llevará a cabo de manera automática.
Ahora sí, ya está todo listo, así que emplea la barra de texto que se muestra en la parte inferior de la ventana para iniciar tu conversación con el modelo. Una vez escrito el prompt, pulsa la tecla enter y la conversación habrá empezado
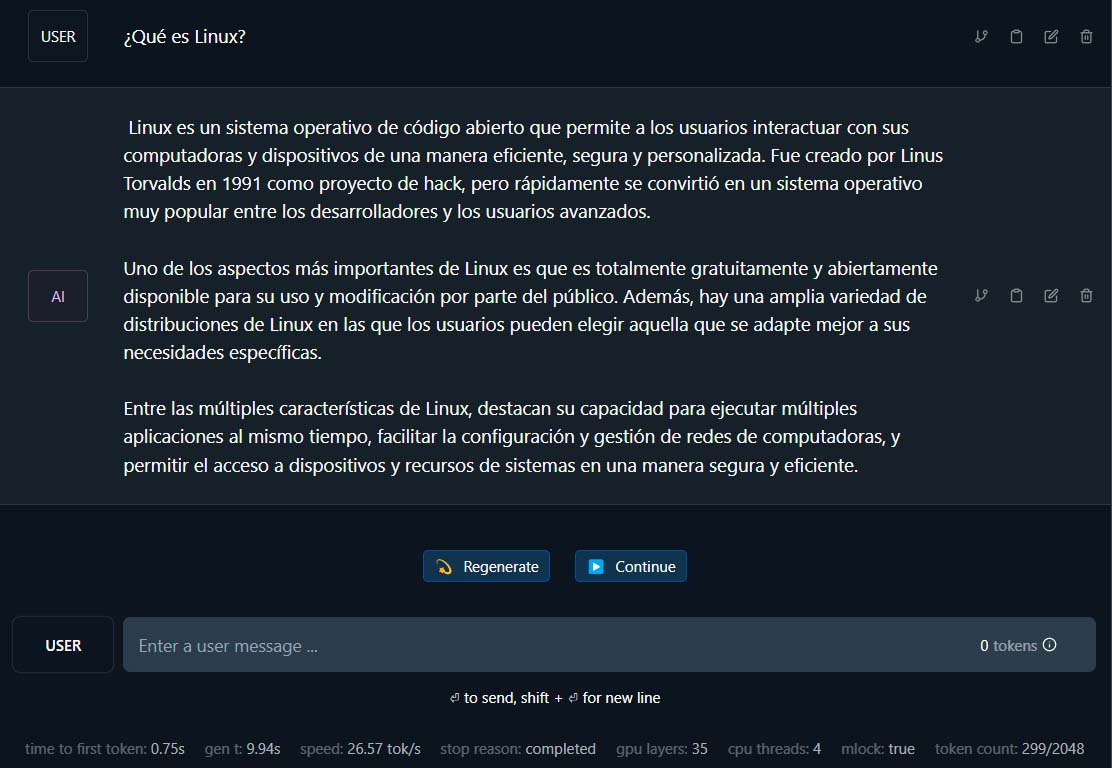
Además, como puedes ver en la imagen superior, al finalizar la respuesta se mostrará, bajo la misma, información estadística sobre la operación.
Por su parte, con el botón «Regenerate» LM Studio volverá a generar la respuesta a tu prompt, mientras que un click en «Continue» le indicará al software que quieres que se extienda en su respuesta.
Como verás, a la izquierda en el recuadro de texto se muestra la palabra «User». Pero, ¿qué ocurre si haces click en la misma? Pues que el texto que se muestra ahí pasará a ser «Assistant». Este modo te permite introducir información que debe ser tenida en cuenta por el modelo durante la conversación, pero sin que deba proporcionarte una respuesta inmediata. Veamos un ejemplo rápido.
Tras cambiar el modo de «User» a «Assistant», le indico al LLM cómo me llamo
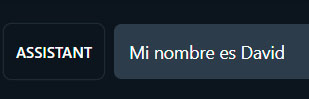
Tras pulsar enter, mi frase se muestra en la conversación, pero no obtengo respuesta alguna por parte de LM Studio
A continuación, vuelvo a cambiar mi rol, ahora de «Assistant» a «User» y escribo un prompt en el que asumo que el modelo ya sabe cómo me llamo. Por ejemplo, le voy a pedir que escriba una poesía con mi nombre. Este es el resultado

Este ejemplo es muy básico, pero imagina el potencial de esta función, pues te permite definir un contexto muy concreto en cada conversación (estas acciones se asocian a la conversación, no al modelo).
Gestionar conversaciones y modelos
Aunque hasta ahora hemos visto cómo instalar un modelo y cómo mantener una conversación, LM Studio te permite tener variedad en ambos sentidos.
En el caso de los modelos, para instalar más tan solo tienes que repetir el proceso que hemos visto anteriormente con aquellos que desees tener. Ten en cuenta, eso sí, que su tamaño es considerable, así que mi recomendación es la mesura. Para revisar la lista de modelos disponibles en tu equipo, tan solo debes hacer click en el icono con forma de carpeta de la barra de la izquierda, y de este modo obtendrás información sobre los mismos

Para eliminar uno, tan solo te debes desplazar, hacia la derecha, y hacer click en el botón de color rojo con el icono de una papelera.
Por su parte, para cambiar el modelo que estás empleando, haz click en el botón «Eject Model» que se muestra a la derecha del apartado superior y, a continuación, haz click en «Select a model to load» para escoger el que quieres emplear a continuación.
En lo referido a al gestión de los chats, como puedes ver al hacer click en el icono del bocadillo se muestra, entre la barra de la izquierda y el apartado central, una sección en la que, de momento, solo se muestra una entrada con el nombre «Untitled Chat», o con el primero de los prompts que hayas empleado en la conversación.

Como ya habrás deducido, para abrir una nueva conversación tan solo tienes que hacer click en el botón «+ New Chat» o, si lo prefieres, emplear el atajo de teclado Control + N. De este modo se añadirá una nueva conversación, desde cero, en la que si lo deseas podrás seleccionar otro modelo. Ten en cuenta, eso sí, que aunque cada conversación te recordará qué LLM has empleado en la última interacción, por defecto en todas se mantendrá el que estás empelando actualmente. Por lo tanto, si quieres que cada conversación se mantenga, exclusivamente, con un modelo concreto, tendrás que asegurarte de escogerlo antes de retomar la charla.
Por su parte, el icono con forma de lápiz que se muestra a la derecha de cada conversación te permitirá cambiar su nombre, para que te resulte más sencillo identificar su contenido de un solo vistazo. Esto es especialmente recomendable si, con el tiempo, terminas por acumular bastantes conversaciones.
Y, seguro que ya lo has deducido, si deseas eliminar un chat, tan solo tendrás que hacer click en la X que se muestra a la derecha de su nombre.
Aunque puedes consultar tus conversaciones en LM Studio siempre que lo desees, también tienes la posibilidad de exportarlas a múltiples formatos. Para tal fin abre la conversación que deseas exportar y localiza, en la parte superior izquierda, el botón «Export». De este modo, se mostrará un menú con todas las opciones de exportación disponibles:
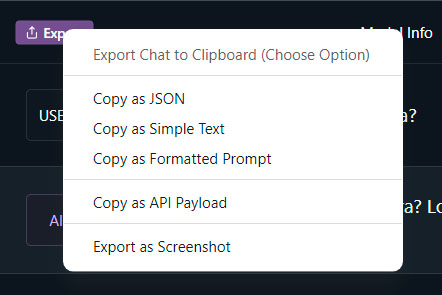
LM Studio cuenta con más funciones y ajustes disponibles, pero con lo que has aprendido en este tutorial ya tienes más que de sobra para empezar a utilizarlo como un profesional. No obstante, una vez que te sientas cómodo con la herramienta, no dejes de experimentar y hacer todo tipo de pruebas, pues así ganarás soltura y llegarás a dominar esta aplicación.











La familia Echo Show, de Amazon, vuelve a crecer

Corsair iCUE LINK LX-R RGB: rendimiento y estética

STALKER 2: Heart of Chornobyl, análisis

Valve actualiza Proton para soportar NVIDIA DLSS 3, generación de fotogramas en Linux

Anker presenta novedades y descuentos de cara al Black Friday

Qué GPU utilizará PS6 y cuándo podría llegar al mercado

Qué placa base elegir: Guía de compras para Intel y AMD

Guía para diferenciar generaciones y gamas de tarjetas gráficas

Ofertas Flash del Black Friday 2024 de PcComponentes

GeForce RTX 5050, especificaciones, rendimiento, equivalencias, fecha de lanzamiento y posible precio

Cómo elegir bien el procesador de tu PC, todo lo que debes saber para acertar

PS5 Pro no cumple con lo prometido, la mejora de rendimiento no llega al 45%
Qué placa base elegir: Guía de compras para Intel y AMD
La familia Echo Show, de Amazon, vuelve a crecer
PS5 Pro no cumple con lo prometido, la mejora de rendimiento no llega al 45%

Juegos gratis: consigue Castlevania Anniversary Collection y Snakebird Complete

Posibles requisitos de Resident Evil 9 para PC

Razer Basilisk V3 Pro 35K, análisis: un ratón a la última para llegar a lo más alto
-
 GuíasHace 6 días
GuíasHace 6 díasQué placa base elegir: Guía de compras para Intel y AMD
-
 GuíasHace 2 días
GuíasHace 2 díasGuía para diferenciar generaciones y gamas de tarjetas gráficas
-
 A FondoHace 6 días
A FondoHace 6 díasOfertas Flash del Black Friday 2024 de PcComponentes
-
 A FondoHace 4 días
A FondoHace 4 díasGeForce RTX 5050, especificaciones, rendimiento, equivalencias, fecha de lanzamiento y posible precio